Keyword [Dendrite] [Dendrite] [Back Propagation]
Sacramento J, Costa R P, Bengio Y, et al. Dendritic cortical microcircuits approximate the backpropagation algorithm[J]. neural information processing systems, 2018.
1. Overview
In this paper, it proposed dendritic cortical microcircuits to approximate the backpropagation algorithm
- introduce a multilayer neuronal network model with simplified dendritic compartments in which error-driven synaptic plasticty adapts the network towards a global desired output
- errors originate at apical dendrites and occur due to a mismatch between predictive input from lateral interneurons and activity from actual top-down feedback
- demonstrates the learning capabilities in regression and classification task
- show analytically that it approximates the error BP algorithm
1.1. In Neuroscience
- growing evidence demonstrates that deep neural networks outperform alternative frameworks in accurately reproducing activity patterns observed in the cortex
- although recent developments have started to bridge the gap between neuroscience and AI, how the brain could implement a BP-like algorithm remains an open question
- understanding how the brain learns to associate different areas to successfully drive behavior is of fundamental importance. However, how to correctly modify synapses to achieve this has puzzled neuroscientists for decades (synaptic credit problem)
1.2. Structure of Pyramidal Cells
- neocortical pyramidal cells can be defined as somatic, basal and apical integration zones
1.3. Future Work
- this paper only focus on a specific interneurons type (SST) as a feedback-specific interneurons. There are many other type interneurons, such as PV (parvalbumin-positive) mediate a somatic excitation-inhibition balance and competition
- consider multiple subsystems (neocortex and hippocampus) that transfer knowledge to each other and learn at different rates
2. Algorithm
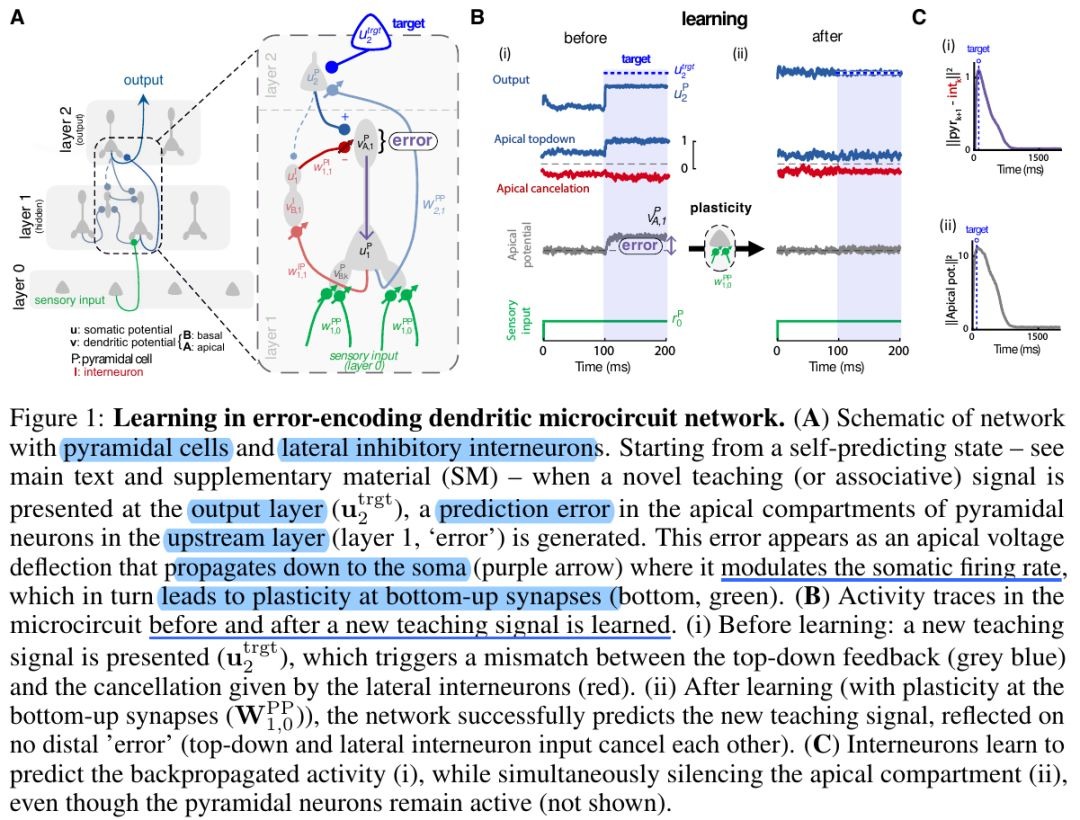
2.1. General Methods
- interpret a brain area as being equivalent to a layer
- propose that prediction errors that drive learning in BP are encoded at distal dendrites of pyramidal neurons, which receive top-down input from downstream brain areas
errors arise from the inability via lateral input from local interneurons (somatostatin-expressing; SST) to exactly match the top-down feedback from downstream cortical areas
cross-layer feedback onto SST cells originating at the next upper layer provide a weak nudging signal, as a conductance-based somatic input current
model weak top-down nudging on a one-to-one basis: each interneuron is nudged towards the potential of a corresponding upper-layer pyramidal cell
recude pyramidal output neurons to two-compartment cell
- feedforward. ignore the lateral and top-down weights from the model
2.2. Interneurons
- receive input from lateral pyramidal cells onto their own basal dendrites
- integrate this input on their soma
- project back to the apical compartments of same-layer pyramidal cells
- predominantly driven by pyramidal cells within the same layer
2.3. Somatic Membrane Potentials Evolve in Time

- k. layer index
- g. fixed conductance
- sigma. controls the amount of injected noise
- lk. leak
- ξ. background activity is modelled as Gaussian White Noise
2.4. Dendritic Compartmental Potentials
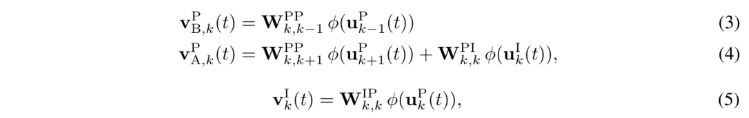
- phi. neuronal transfer function
- B. basal dendrite
- A. apical dendrite
2.5. Teaching Current
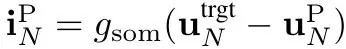
- an interneuron at layer k permanently receives balanced somatic teaching excitatory and inhibitory input from a pyramidal neuron at layer k+1 on a one-to-one basis (u_{k+1}^P as target)
- the interneuron is nudged to follow the corresponding next layer pyramidal neuron
2.6. Synaptic Learning Rules
2.6.1. In Previous Works
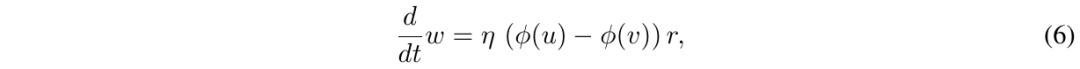
- w. individual synaptic weight
- η. learning rate
- u. somatic potential
- v. postsynaptic dendritic potential
- phi. rate function
- r. presynaptic input
2.6.2. In this Paper
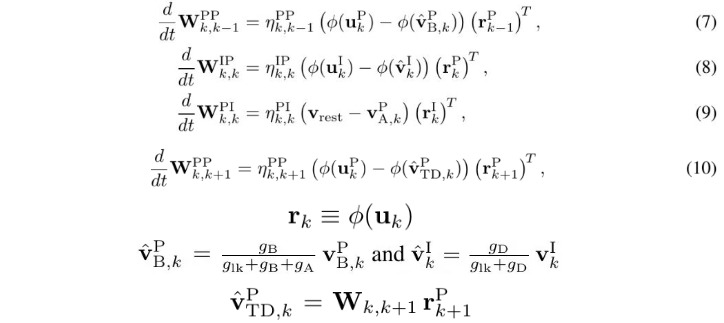
- v_rest = 0. resting potential
- ^. take into acount dendritic attenuation factors of different compartment
2.7. Self-predicting
- no external target is provided to output layer neurons
- the lateral input from interneurons cancels the internally generated top-down feedback and renders apical dendrites silent
- this paper demonstrate that synaptic plasticity in self-predicting nets approximates the weight changes prescribed by BP
- only W^IP and W^PI are changed at that stage
- the interneurons will learn to mimic the layer-(k+1) pyramidal neurons
- Once learning of the lateral interneurons has converged, the apical input cancellation occurs irrespective of the actual bottom-up sensory input
- help speed-up learning, but is not essential
3. Experiments
3.1. Self-predicting & Training
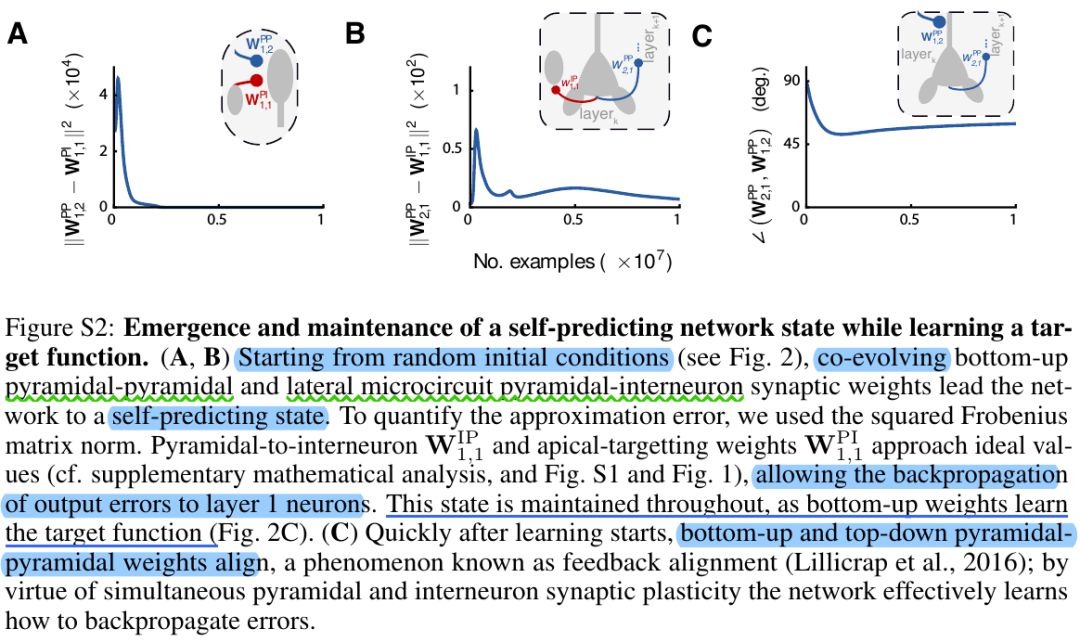
- A. top-down weight = - i-to-p weight
- C. aligned 45°
3.2. Regression Task
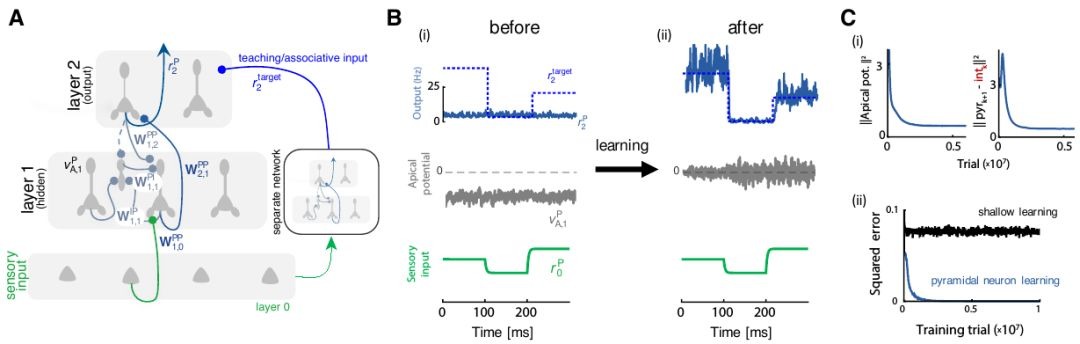
- Network. 30-50-10 (with 10 hidden layer interneurons)
- learn to approximate a random nonlinear function implemented by a heldaside feedforward network of 30-20-10
- W^PP, W^PI, W^IP all are random initialized with a uniform distribution
- top-down weight matrix is kept fixed (top-down and interneurons-to-pyramidal synapses need not to be changed)
- relax the bottom-up vs top-down weight symmetry
3.3. Classification
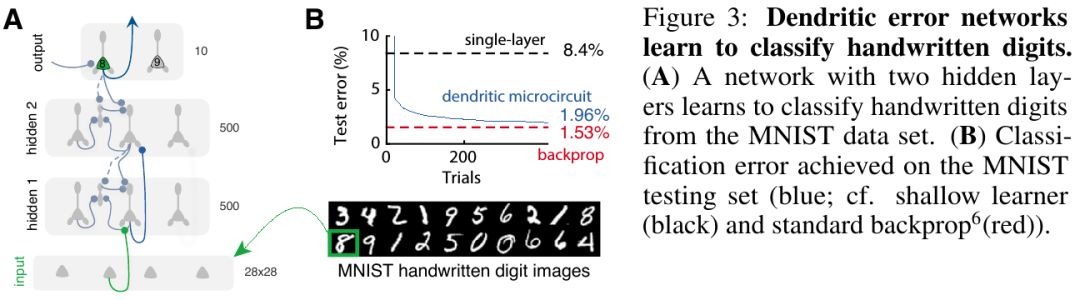
- Network. 784-500-500-10, initialized to a random but self-predicting state
top-down and i-to-p weights were kept fixed
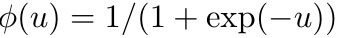
epical compartment voltages remained approximately silent when output nudging was turned off, reflecting the maintenance of a self-predicting state throughout learning
both pyramidal and interneurons are first initialized to their bottom-up prediction state
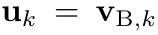
output layer neurons are nudged to their desired target, yielding updated somatic potentials
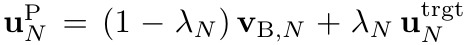
k=N-1 to 1
